In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the. Llama 2 is here - get it on Hugging Face a blog post about Llama 2 and how to use it with Transformers and PEFT LLaMA 2 - Every Resource you need a. Code Llama is a family of state-of-the-art open-access versions of Llama 2 specialized on code tasks and were excited to release integration in the. This release includes model weights and starting code for pretrained and fine-tuned Llama language models ranging from 7B to 70B..
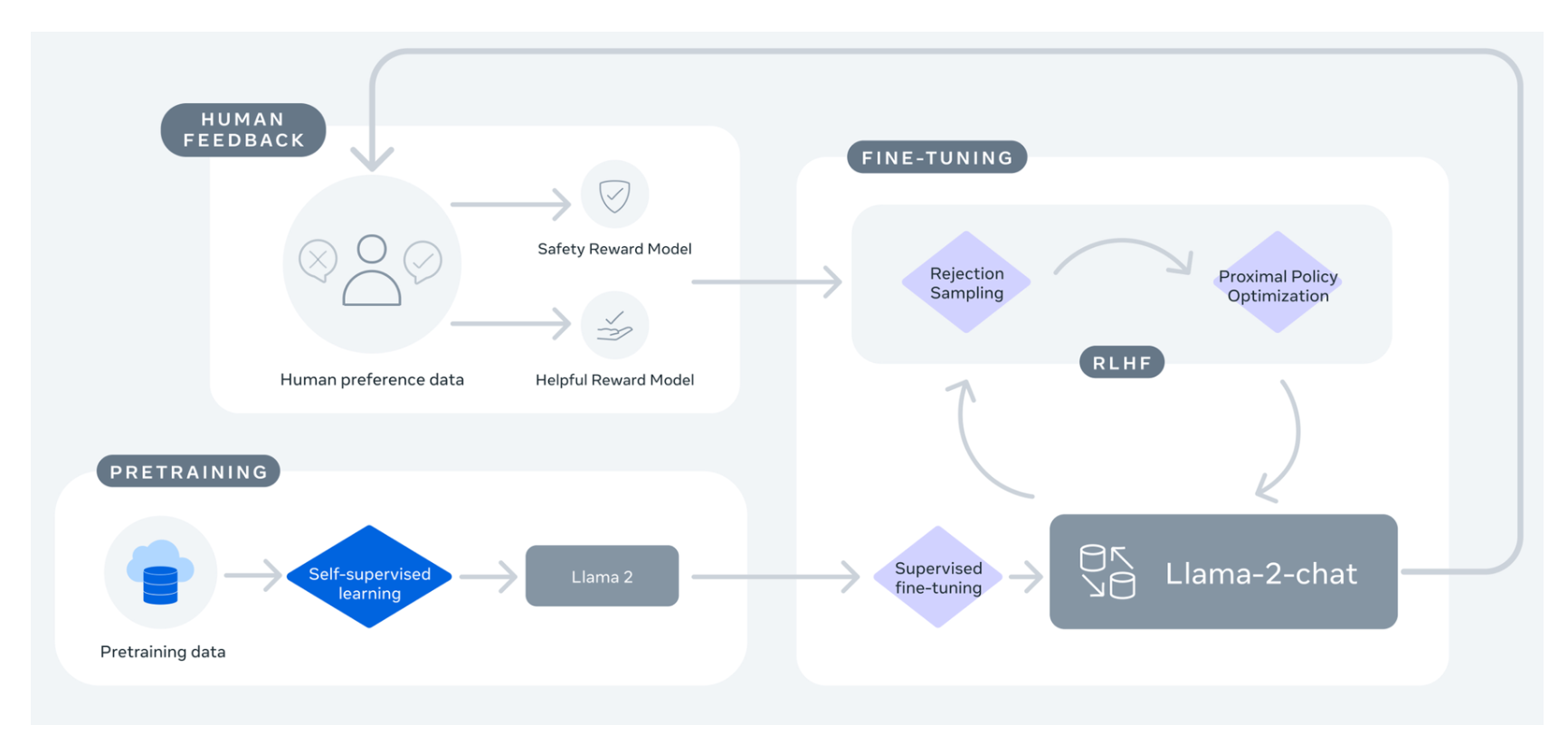
Blog Llama2 Md At Main Huggingface Blog Github
A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. As usual the Llama-2 models got released with 16bit floating point precision which means they are roughly two times their parameter size. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion. The 4bit 70B model is 35GB With overhead context and buffers this does not fit in 24GB 12GB..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in. We introduce LLaMA a collection of foundation language models ranging from 7B to 65B parameters We train our models on trillions of tokens. This paper proposes an approach to detection of online sexual predatory chats and abusive language using the open-source pretrained. We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models. In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2-Chat at scales up to 70B parameters..

Starfox7 Llama 2 Ko 7b Chat Ggml Hugging Face
A bigger size of the model isnt always an advantage. Open-source models combined with the versatility of the Hugging Face platform ensure that developers and researchers worldwide. Llama 2 is much faster and more efficient than GPT-35 and GPT-4 making it a good choice for tasks that require real-time. Llama 2 tokenization is longer than ChatGPT tokenization by 19 and this needs to be taken into account for cost Despite this Llama 2 is 30. Llama 2 vs GPT-4 Comparison 9 Key Differences between Llama2 and GPT-4..
No comments :
Post a Comment